“这篇论文质量怎么样?”在学术界,这个问题看似简单却很难回答。说它“好”,好在哪里?创新性突出,还是论证充分?长期以来,论文质量的判断依赖审稿人和导师的主观经验,同一篇论文不同专家可能给出截然不同的评价。这种主观偏差,困扰着期刊编辑部和高校研究生院,也让作者在修改时无所适从。如果让AI来打分,它如何理解“创新性”?又如何判断“论证充分”?近日,随着维普斟知智评系统的正式上线,这些问题有了可操作的答案。
把“感觉”变成“数字”
打开一份智评系统生成的报告,首先映入眼帘的不是笼统的评语,而是一串串数字。以“创新性”为例,系统将其拆解为“关键词罕见度”和“参考文献组合新颖性”两个可量化指标:前者对比同领域论文的关键词使用频率,评估选题独特性;后者分析参考文献的年代分布和学科交叉程度,判断研究视角的新颖性。
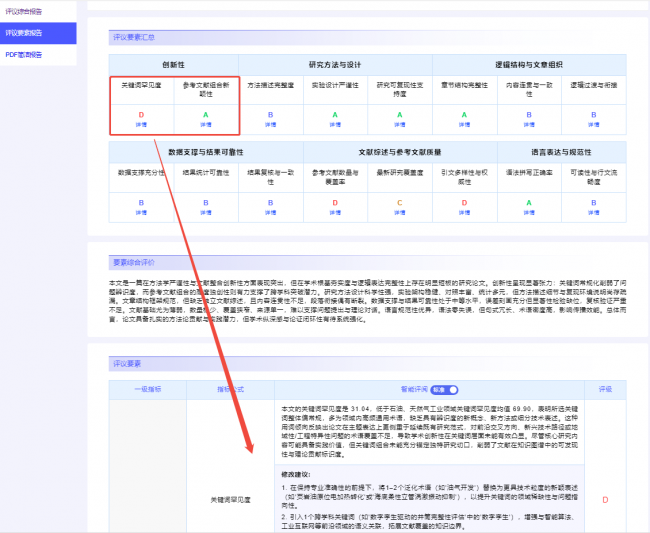
“研究方法与设计”维度下,细分为“方法描述完整度”“实验设计严谨性”“研究可复现性支持度”三项指标,系统会检测研究步骤是否清晰、实验设计是否存在漏洞、数据是否足以复现结果。“文献综述与参考文献质量”则从“参考文献数量与覆盖率”“最新研究覆盖度”“引文多样性与权威性”三个角度切入。维普斟知产品团队表示:“我们不是让AI替人做判断,而是让AI把人做判断需要的依据摆出来。”
20余项指标,多维评价体系
智评系统围绕底线合规性和研究质量两大板块,拆解出20余项细化指标。底线合规性包括意识导向合规、题文一致性、事实准确性、论文文本检测、AIGC痕迹检测等,解决论文是否存在“硬伤”的问题。研究质量则聚焦研究方法、研究结论等核心维度,每项都有量化得分和数据支撑。
系统推出三种报告形式:综合报告将底线合规性与研究质量分开呈现,形成“合规基础保障+质量核心优势+待改进项”的结构化结论,适合主编终审、学位评定等全局视角;要素报告像详细“体检单”,20余项指标逐一评分并给出改进建议,适合深度修改和指导;简洁报告一页浓缩核心结论,适合快速沟通与存档。

三大版本,因需而变
针对不同用户,维普斟知智评系统推出大学生版、研究生版、期刊版,内置差异化评价体系。大学生版侧重基础规范,帮助本科生自查格式、引用和AIGC使用问题;研究生版向学术深度延伸,聚焦选题创新性、研究方法科学性等抽检核心维度,支持批量检测,为高校提供质量分析报告,实现抽检问题前置预警;期刊版强调审稿效率,初审可快速过滤不合格稿件,据测算初审效率提升80%左右,专家评审耗时缩短约40%,评审一致性提升50%-60%。
AI打分,靠不靠谱?
准不准,取决于AI“学”了什么。维普斟知智评系统背后是维普近三十年学术数据积累和自研垂直领域大模型。系统可调用学术论文库、硕博论文库、期刊会议库等海量数据,自研模型经过学术语料训练,对学术文本的理解更精准。评价指标体系经过多轮专家校验,确保量化评分与专家判断一致。
从“凭感觉”到“看数据”
当前,国家对学术质量刚性约束持续强化,高校和期刊社面临从“经验驱动”向“数据驱动”转型的压力。AIGC普及带来的新挑战,如识别AI生成内容,传统手段难以应对。维普斟知智评系统集成的AIGC痕迹检测模块,采用多模型融合算法,逐段分析文本风格,为管理者提供客观依据。
“AI打分的意义,不是贴标签,而是把‘好’拆解成可理解、可改进的具体维度。”维普斟知市场负责人表示,“当论文在20多个指标上的得分一目了然,作者知道往哪改,导师知道在哪指导,编辑知道审稿重点——这才是AI赋能学术质量的真正价值。”让每一篇学术论文都经得起检验。这是维普斟知成立时确立的宗旨,也是智评系统试图抵达的目标。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。