在学术出版的数字化版图上,两条技术路径曾长期并行不悖。一条以玛格泰克为代表,从排版自动化切入,用二十余年时间将期刊的版式处理推向极致。2012年《福建农业科技》启用玛格泰克系统时,编辑们最直观的感受是“版面调整的时间省了一半”。另一条以方正鸿云为代表,以XML结构化数据为唯一驱动源,重构学术生产的底层逻辑。据方正电子官方数据,采用鸿云系统的期刊,XML排版效率提升35%,审稿周期缩短20%以上,出版时滞缩短超50%。

一个强在“怎么把论文排好看”,一个强在“怎么把数据管规范”。它们各自在垂直领域建立了深厚壁垒,却也共同留下了一个未被回答的问题:当排版和结构化各成体系,谁来把这两个环节“串起来”?这正是维普斟知采编系统试图用“一站式AI”回答的命题。
从“数据孤岛”到“智能血液”
鸿云的核心价值,在于让论文变成“机器可读”的结构化数据。一篇符合JATS标准的XML文件,可以让参考文献自动延展阅读,可以让内容在多平台一键发布,可以让搜索引擎更快抓取。国际学术界早已达成共识:结构化内容与AI的结合,正在重新定义出版效率——当稿件以结构化形式进入系统,每一个部分(标题、作者、摘要、参考文献、图表)从一开始就是机器可读的,AI工具可以自动核查参考文献、验证元数据、甚至建议语义标签。
但鸿云的局限在于,它的结构化发生在“生产环节”,而非“全流程”。投稿阶段的数据、审稿阶段的意见、编校阶段的修改,往往以非结构化形式散落在不同系统里,等到进入XML生产时,这些宝贵的信息已经流失殆尽。
维普斟知的做法,是将“结构化”从生产环节前置到全流程。从投稿那一刻起,每一份稿件就以结构化形态存在;每一次审稿意见,都被打上标签归入稿件的数据包;每一轮修改,都带着版本信息和修改痕迹流转。当稿件最终进入排版环节,它已经不是一个“待处理的文档”,而是一个“自带履历的数据体”。
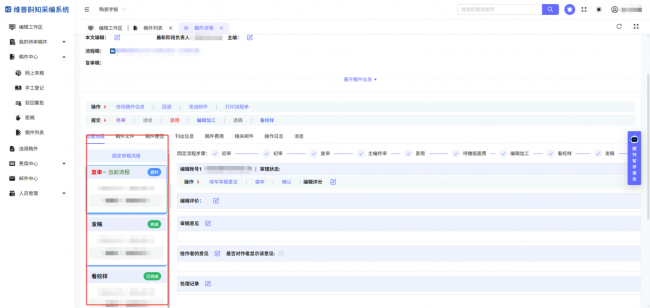
这种设计,让数据不再是流程的“副产品”,而成为贯穿始终的“血液”。正如某前沿研究机构所预言的,未来的学术出版将实现“从基于规则和经验的工作流,转向数据和代理驱动的流程”。
AI如何“打通”而非“叠加”
玛格泰克和鸿云并非没有引入AI。玛格泰克在智能排版领域持续探索,鸿云也集成了AI辅助审稿、AI写稿检测等功能。但它们的AI能力,更像是“叠加”在既有流程上的工具——排版时加一个智能推荐,审稿时加一个辅助检测,各自为战,互不连通。
维普斟知采编系统的差异在于,它的AI不是“工具”,而是“粘合剂”。投稿阶段的维普斟知AI智评,生成的报告可以直接辅助审稿;审稿阶段的意见,可以自动转化为编校环节的修改建议;编校完成后的稿件,可以直接触发排版引擎生成版式。每一个环节的产出,都是下一个环节的输入;每一次AI介入,都在为全流程积累数据资产。
重新定义“采编系统”的边界
玛格泰克和鸿云各自守着一方城池,用二十余年时间证明:排版可以很专业,结构化可以很极致。但当学术出版从“数字化”迈向“智能化”,当期刊编辑部越来越渴望从重复劳动中解放,当作者、编辑、专家期待更流畅的协同体验——单点突破的“工具思维”正在触及天花板。
正如中国激光杂志社在一篇行业观察中所言:“真正的变革并非简单地将AI嵌入旧系统,而是需要从根本上重新设计一个人类与机器深度协同、以规模化且可信赖为目标的智能工作流。”
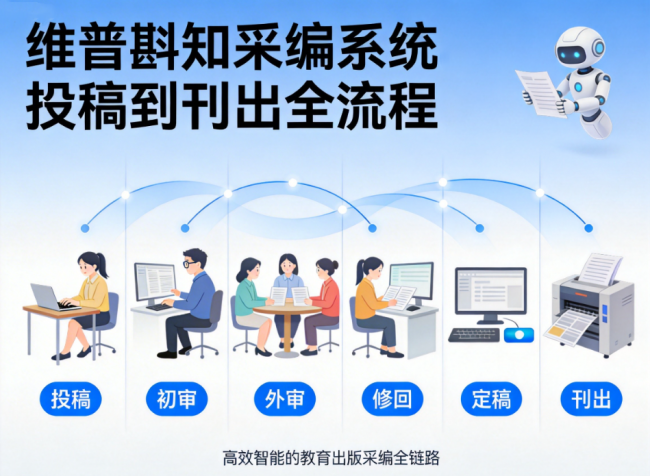
维普斟知的选择,是重新定义“采编系统”的边界——它不再是一个“记录流程的工具”,也不仅是某个环节的“效率放大器”,而是一个用AI贯穿全流程的“智能协同平台”。在这个平台上,排版和结构化不再是两个独立的环节,而是同一套数据的不同呈现方式;投稿、审稿、刊出不再是先后串联的工序,而是并行协同的生态。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。























































































